Masking of the cost volume calculated
The cost volume, a 3D matrix (of size n x m x p where n x m is the size of the left and right images and p is the number of disparities) containing the similarity coefficients. The cost volume is calculated during the Matching cost computation step by the selected similarity measure (SAD/SSD/CENSUS/ZNCC/MCCNN).
The cost volume is associated with a map of calculation validity indicators, i.e. the validity of the value of the similarity coefficients. These criteria are stored in a map validity_mask. Some are even pre-calculated before the similarity coefficients are obtained, see the page on Validity criteria, and are those obtained by:
minimum and maximum disparity
no data in the left and right images
invalid point in the left and right image mask
However, the invalid points present in the left and/or right masks for some disparities can only be taken into account once the cost volume has been calculated. The cost volume is calculated using a matrix product for optimisation purposes and would therefore replace the nan point values for some points and disparities.
The purpose of this page is to explain the cv_masked method, which adds nan in the cost volume corresponding to the invalid points present in the left and/or right masks.
Search for column coordinates based on disparity
To better understand how the disparity search zone works, let’s first look at what happens for a point  .
.
Note
For all the examples below, the disparity search interval is ![[-3, 1]](data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAAC4AAAATBAMAAAAdcyJ3AAAALVBMVEX///8AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAADAOrOgAAAADnRSTlMAv8+LYN2dr/sY6UgydC2RIF4AAAAJcEhZcwAADsQAAA7EAZUrDhsAAACFSURBVBjTYxAyYMAEzOoMCgzYABNCnNlMDcJgWY0iXszAlwCiebJfo4iXMnBA2ajiDAzzDLCLZzFgFTcUwC7OYDoBRdw1FAiCgXzWBdjUazMwvsQizvOWgekBNvWVDDMSeDRBrCco4mxlugzczQwMnEWvqlHdAwS8mOGGV/wCQXHs8aUIAE/fHXWRq1m3AAAAAElFTkSuQmCC) .
.
The animated image below shows the disparity search range in orange on the right-hand image for the point on the left.
Note that for  , this is outside the image, so the cost volume is filled with np.nan for these exceptions
(
, this is outside the image, so the cost volume is filled with np.nan for these exceptions
(![cost\_volume[i, j, -3] = np.nan](data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAAO4AAAATBAMAAABlzCzWAAAAMFBMVEX///8AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAv3aB7AAAAD3RSTlMAdIsyz6+d6RhI87/7YN1/I6gaAAAACXBIWXMAAA7EAAAOxAGVKw4bAAAC9klEQVRIx61WTWgTQRT+9i/Z/GyzTTWtFGQbqymKuFB6syQWU5UebKUg6sHY1pMItaDgbetFD4WsFG9C47EHtS22Fw+mVcQcCltERVEIPagnCQ1Ke6pvdreQxNo2IQ+SeTNv5vtm3l8CVCmBnv/b+CTqI5dn/lkSd9ov1kr0oHzqVbeDVjKufrLUEB1J1c77vXwaMrbjFSxXHy9ZlzT8qZ13o3z6Ze+ulPJ4UzOvL1s+v1JNCOW1qni5tiZwQ5coQNHui7c1xt6KCR2RwybG8HAGrTjSET03vs8EwhGCJrMjK+VZ5xmt4OWG7rWbiAxH2b4IYdCea5Ouhh4ksUApwmmS1qDZYQuaXiuQErIoymoOvcLnJTSrXB5iSrFEZrZhFf1UWRG9dJ3x4jQJq6juxxqXl1vWMEc5QRgHgVWccTW6ZQs/ipAp3ZUR0tlBawoePUbBVrKKr4Acx2dwFJ4EfUm6CCvuEuFJefX+rHivyg4pShaD9HbCGAGfR9LREKInBjWkTeH5Ir46BwYJcwnyhpSAlBAKCPSjFw0pPAvfZNBbUZfX7Wf/YsIc9aMyvvPkIXbfPtZvGAYRLTsa4lQqcR0nyBVX2cWYPAUvFMEXvBr8Ft0xaCGHtC4XnbzKbcUvU5pvJl4ZFbzLzIENKhZJJ4wiEZH/bA1TdG/63MEtBDEm241iHZNk96ZCnWbIEFNqHPTomCIXbF4u49ZvoDSv4irOV8SXDjUr1APsPhMHN8oCmLdsDX4dh/wmn0ACHzHtgcOrYRrtSPMIYeK9FWOBWeBpjTNFSP2acJZt86vO6NSvIb+t8DOlzTyPKcNr0r4Y+VcL4n6/ZmsQBsKGMBAFvjVqiDRhc3MT+8NAV1iDdBz87MoFDEFS8UFFV2MHq6MBw7fEcNPu6Mj1EbWC16PhUQtutA3D95ow6Jwye2DOsLWqW4sDzbndjNu9qazW5yeqhDe5J95iPXkp/SY639njLry+Qp15xWP6Xng//a4P747/N/r2DPMXCku1FiAkQJkAAAAASUVORK5CYII=) ).
).
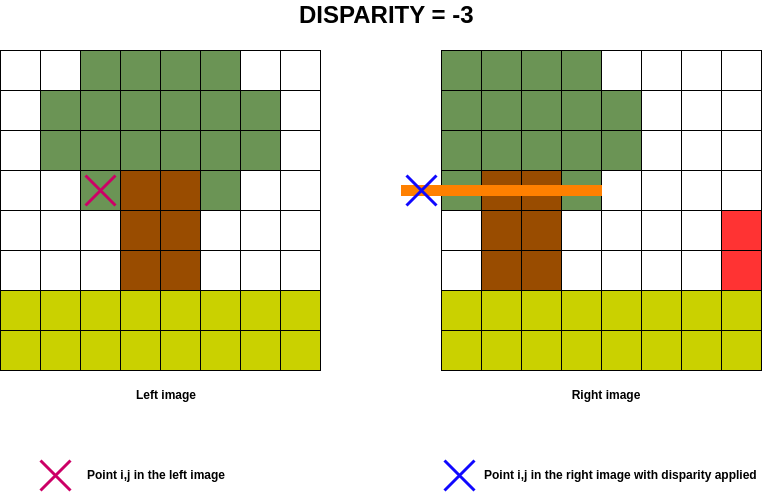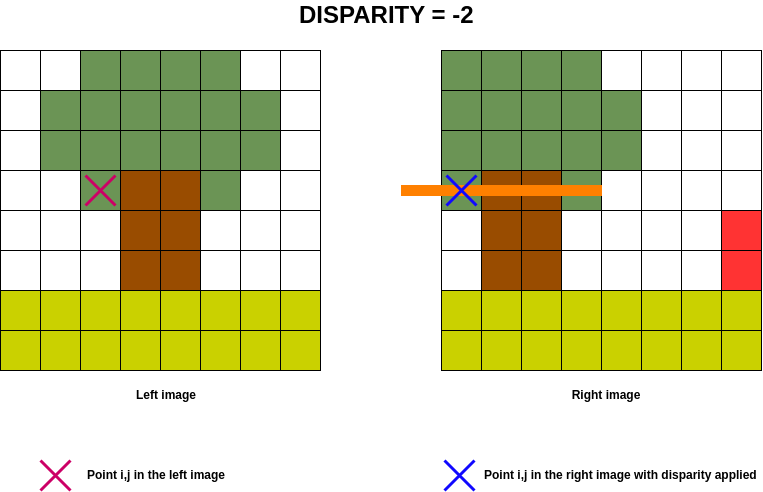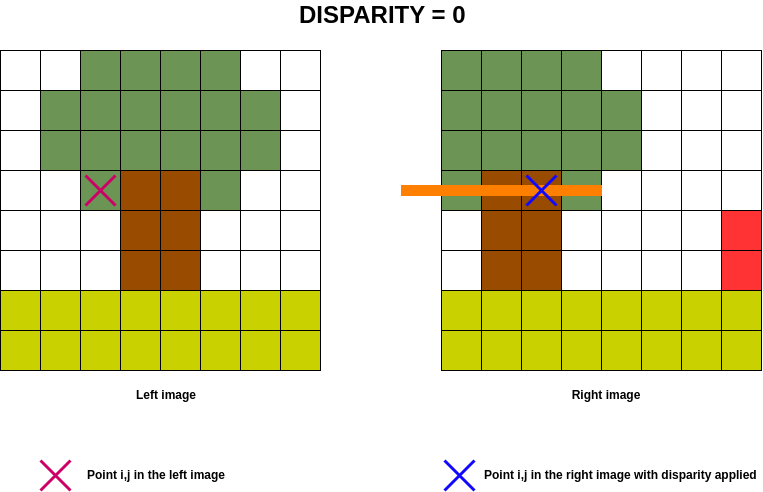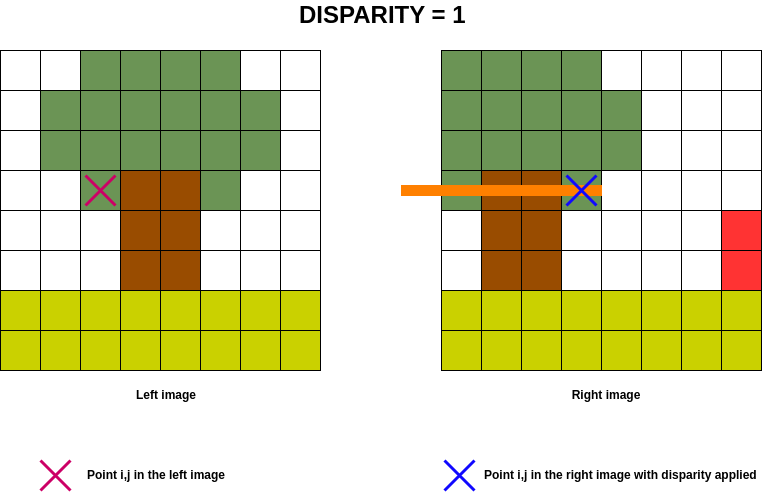
In order to optimise calculations in the cost volume, the aim is to determine which column of the left image will be present in the right image for a given disparity, given that the disparity implies a column shift on the right image.
In the previous example, we are looking to see which columns in the image on the left are present in the image on the
right for a disparity between  and
and  .
.
Note
A negative disparity implies a shift to the left on the right image and vice versa for a positive disparity. For a null disparity, no shift is applied.
The following image shows the areas of the image on the left that can be treated for disparity and its equivalent in the image on the right.
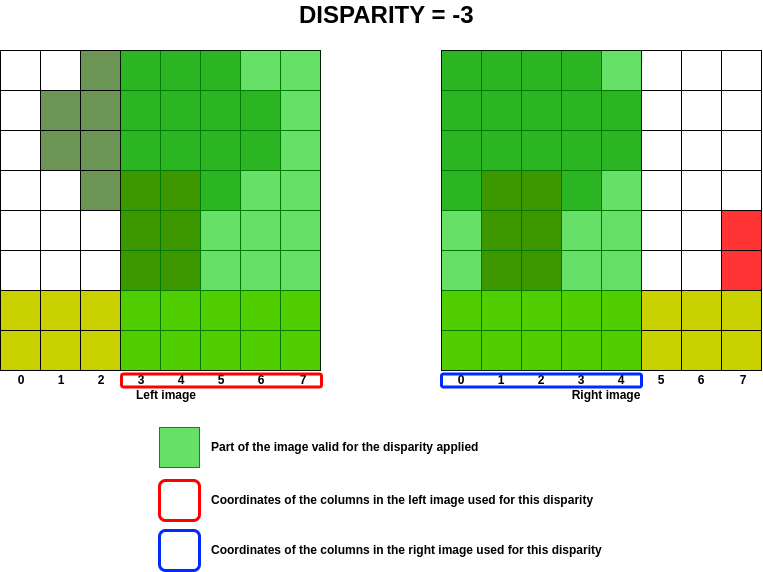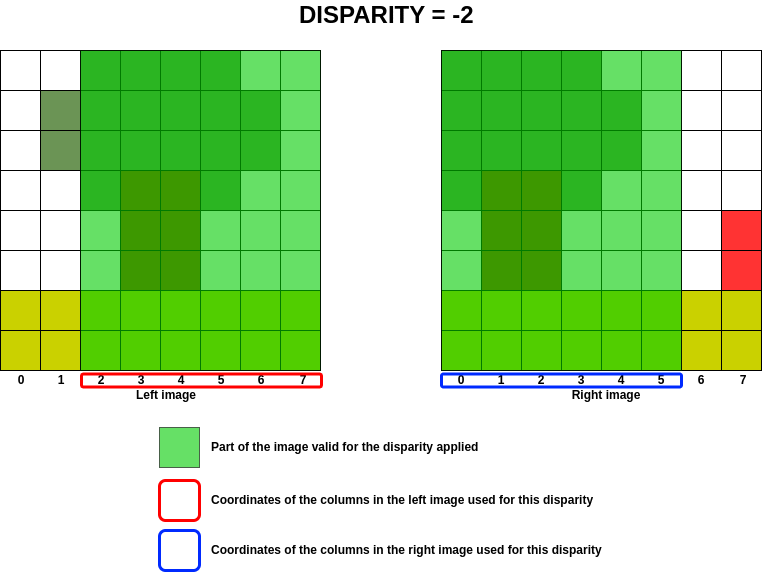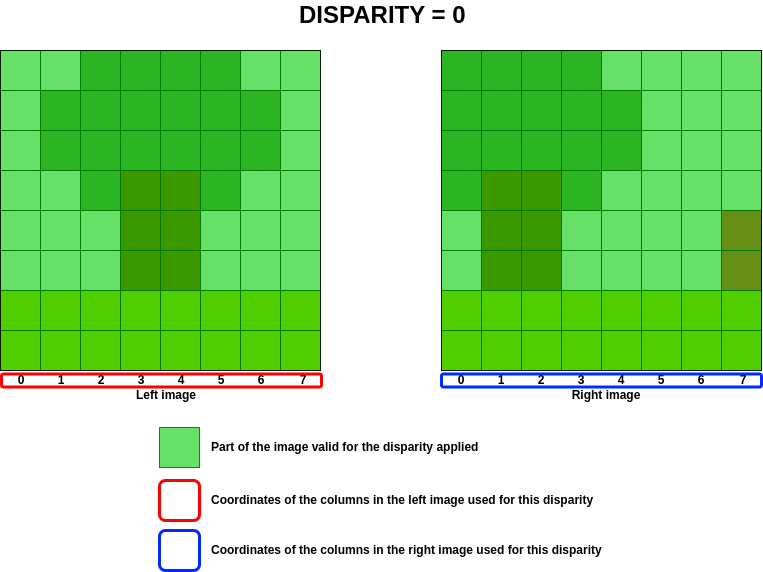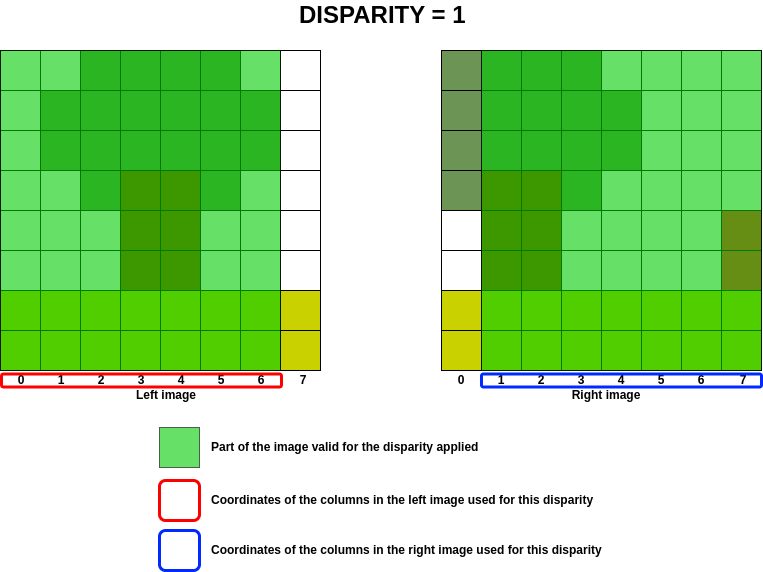
At best, the range of columns treated for a given disparity corresponds to the following equations:
Equations
Equations to determine the first and last column coordinates as a function of disparity:


With,  &
&  which correspond to the column coordinates of the left and right images respectively and
which correspond to the column coordinates of the left and right images respectively and  the current disparity.
the current disparity.
Example
In our previous example, for a disparity of -1 :


These indices are used to match the marker in the left image to that in the right image for disparity  .
.
The subpixellic
In the matching cost step, the subpix parameter allows cost volume oversampling, i.e. testing floating values between two integer disparities. For examples, with subpix = 2 value 0.5 will be tested. With subpix = 4, values 0.25 and 0.75 will also be tested.
This introduces an offset of the right column image and therefore of these coordinates too, but only for the right image. This shift leads to a modification of the code, as the previous equations are no longer verified.
Example
In our previous example, for a disparity of  the left image has the same coordinates (i.e.
the left image has the same coordinates (i.e. ![[0, 1, 2, 3, 4, 5, 6, 7]](data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAAIYAAAATBAMAAACn/GhSAAAAMFBMVEX///8AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAv3aB7AAAAD3RSTlMAv8+LYJ2vSOky3XT7GPOCPBn4AAAACXBIWXMAAA7EAAAOxAGVKw4bAAABzElEQVQ4y62UPUsDQRCG3zOXu1xCJIofYGNs7MRAiHWKVLGRiFoomIgoYhMbtRARBG2Df8CICIoI9xMkwUIQTGWrYqGdkShRRM7dmb3IpVLiFju77808NzM3HDpjaG35BhFFq6tNMPTxeb7ou2z9uVM+xDNjym+VdmsnccL3xERBGmM6lcpLxjoCJFhTdXZYwi0VaMTwphj3zHgukSc0W6P82xzHiUnGKfwR9lSMR2h3xCiipGoeYIatkGmYefIQSVMtdejnHkYZRpVP4RrbtQ4v40FZHchKhvkB88vDAIJbqjPKxhRjfCRJh8/4svtVCpKhC8ZHE2M/zw4dyhF8CI+JOiXrBUGV0g1UHnozY9t9yxmXohhi9cnNrMF3x/deYlh1hJpqMRpzd8yl/DBmKI/XRkiV50MI3p4iroYnj/6KzKZn4WlRCu02ZrkfLkNGSsYh/FEPQ7dBiezbGFbUA9rFHFEtOIKfa9G2mJEWz6whqbwCe+LFK6nRiBSMSviCBMmQgq8SviRhE4EkhQSLzAhNz8Msi67PvS9iQ2Rw7TgRKWAyY5OA1aslEhK5AglmdxeFQMsygwtzm+aO0e+Ff2X8PbQh/A+j9f/YwDeIbnsa+U71WAAAAABJRU5ErkJggg==) ) and the right image has new coordinates
) and the right image has new coordinates ![[-0.5, 0.5, 1.5, 2.5, 3.5, 4.5, 5.5, 6.5]](data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAAQMAAAATBAMAAABmXnXXAAAAMFBMVEX///8AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAv3aB7AAAAD3RSTlMAv8+LYN2dr0jpMnT7GPOm9b5MAAAACXBIWXMAAA7EAAAOxAGVKw4bAAACcklEQVRIx82WP2gTURzHv/GS8+Vfe0jr4CCZRBQxtRgnIYMRRKGFoqAu0aJFFFpp1cF/5ygU063Q6XAQpKDnooug6CB0yqRLwYKL4GBLHUpiqO+9e+/yPYdumr4hL9/f5967T373EoJdZfR0HJlCCT0epa5CenxGTc+nrwQ6nzxWla+5+cqFiJ/yE3hiMGTsVPYlMMQUY1OPceVqHEnhMbKq/OL3gWiLOSyoTX5+iBY9a2gFi3cGxXXG0+ivEwb6PMambnEqTJVsJIWLcNWqRRMzIS6pTULL+7WCxX0+9jK+hUKJsHzGHuPFxIQahG8jKWwg/Z6uknc8s4VCoYyHCYyvZVYQj7ZS+EaxqyBaEB3V8GF9JNAI0GjKTcb1kYgVLJbjPBjjWgI7KY+xqVvcHr4bx65CuqUsgM+qx3KMBMoCxTq+s4LFcvsNMB7yErisFWJs6mbKrannbGKiC+lWdFZGTRdGoqM0yAoWA1nzg2IwjjYJC18rEDbL9CTW4azYqBRqZ+UYkx8q39FlVx0JvPTxLtr0RlIhwuo7AMbIzBF2YBUsNsv0lPtF96LjKMsK/4C7qu9YxVt18kNMsoLFcHQTYrwfqQ7hoTsP5n3Cpm5xO1LQkRTG4Kr3C6ZlmTIuq3YHyQdhMU7LT9rFuTZ2rDJGxuPVpm7xObgrNpJCTS7IHcJxLKsJ6VF5xdOm0ywuySlqC2ExcOIV4/tYrhPWCoRN3eInyFZNZIX89RmIJTgTeyA+yvz6TRWzASo3A8zKpn85PO8TLmxurjF2bx9MrBb3PgWEdb2Lxe4BG1mBR/6vHP5DvH0Vwv9otC0Uev6vyfsD/V/6vLrPmWIAAAAASUVORK5CYII=) .
.
With the above equations:


The expected result is:


In this case, a search for the nearest coordinate is carried out to obtain the correct range of left and right image coordinates.
if self._subpix != 1 :
if disp < 0:
`Coordinates{Left}{0}` = find_nearest_column(Coordinates{Left}{0}, Index{Left}, "+")
`Coordinates{Right}{-1}` = find_nearest_column(Coordinates{Right}{-1}, Index{Right}, "+"))
else:
`Coordinates{Left}{-1}` = find_nearest_column(`Coordinates{Left}{-1}`, Index{Left}, "-"))
`Coordinates{Right}{0}` = find_nearest_column(Coordinates{Right}{0}, Index{Right}, "-")
Warning
What was explained above is only valid in the classic case of Pandora, i.e. without the use of a step and a ROI.
The case of step
The use of a step in image processing can only be done via Pandora2D, see doc matching cost Pandora2D.
This constraint means that the previous equations can no longer be used. In this case, the possible coordinates for the left image are those identified in the cost volume by the coordinates of the cost volume columns.
Then, an increasing search starting from the first coordinate for a negative disparity, and a decreasing search starting from the last coordinate for a positive disparity, is performed in order to obtain the correct interval.
Then, the formula  is applied.
is applied.
The case of ROI (Region of Interest)
The ROI can be enabled by the user, if they use Pandora in library or notebook mode.
Reminder
The ROI configuration is as follows, see doc Region of Interest Pandora2D.
"ROI":
{
"col": {"first": <int>, "last": <int>},
"row": {"first": <int>, "last": <int>}
},
In this case, the coordinates of the left and right images no longer start at zero, but at [“row”][“first”] and [“col”][“first”]. If the user provides the images or ROIs themselves, they must check that images or ROIs begin with the same coordinates.
Apply Left/Right masks on cost volume
From the previous section, once the coordinates of the left and right images have been identified for a given disparity, the coefficients of the masks for those images are applied to the cost volume.
Note
A mask can contain different values, but in Pandora the valid pixel value is  .
.
The masks supplied by the user are transformed into images containing and NaN, with being the valid pixels
and all other values are set to NaN.
For each disparity, the coordinates of the left and right images are calculated and those same coordinates
are used for the masks to add NaNs to all the “invalid” pixels.
The image below shows what happens for the previous example at disparity for only one row.
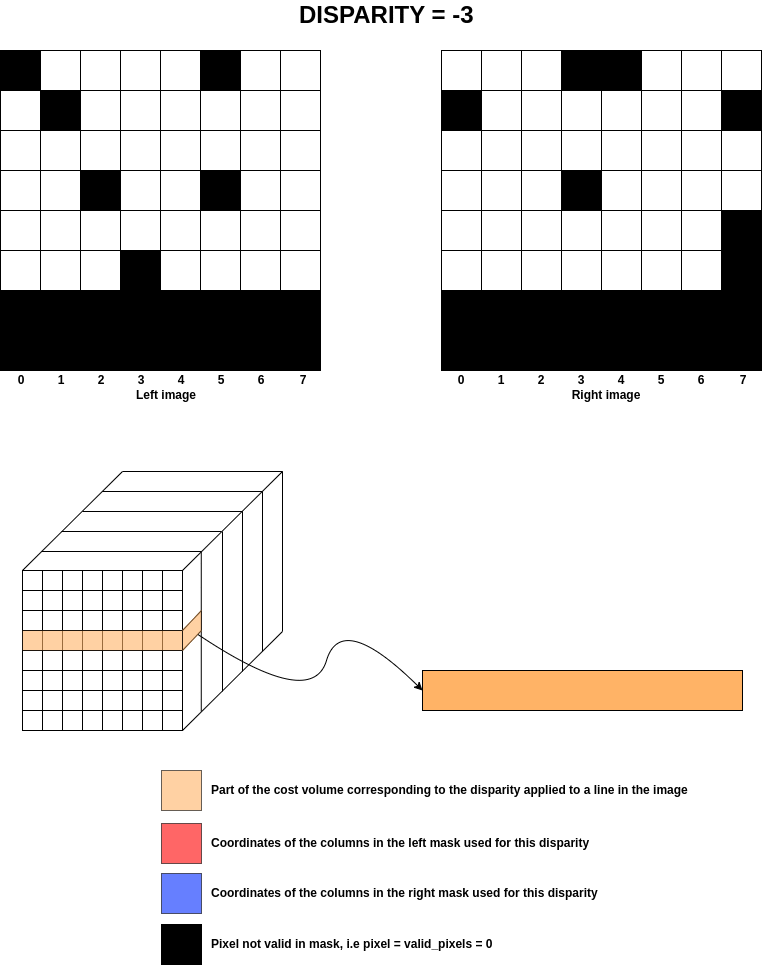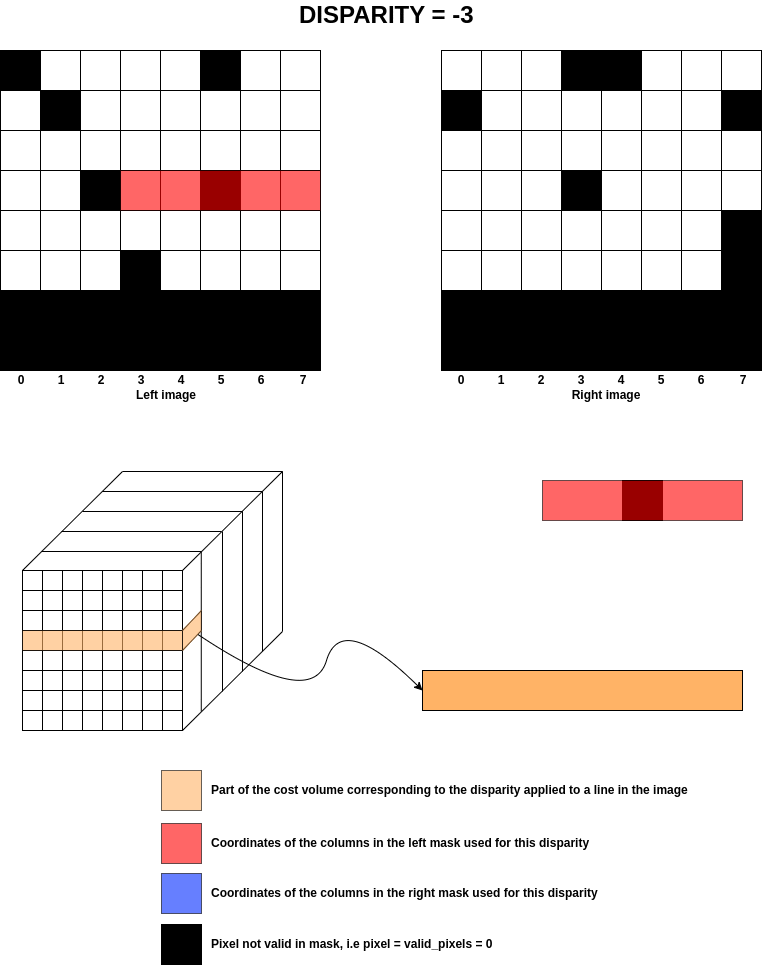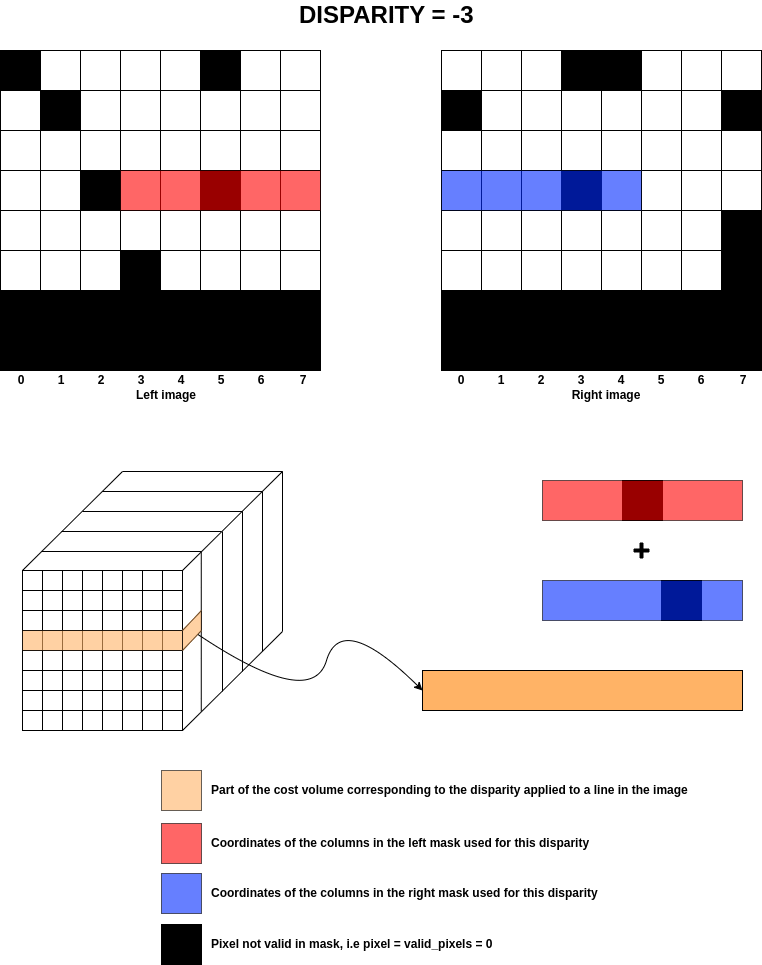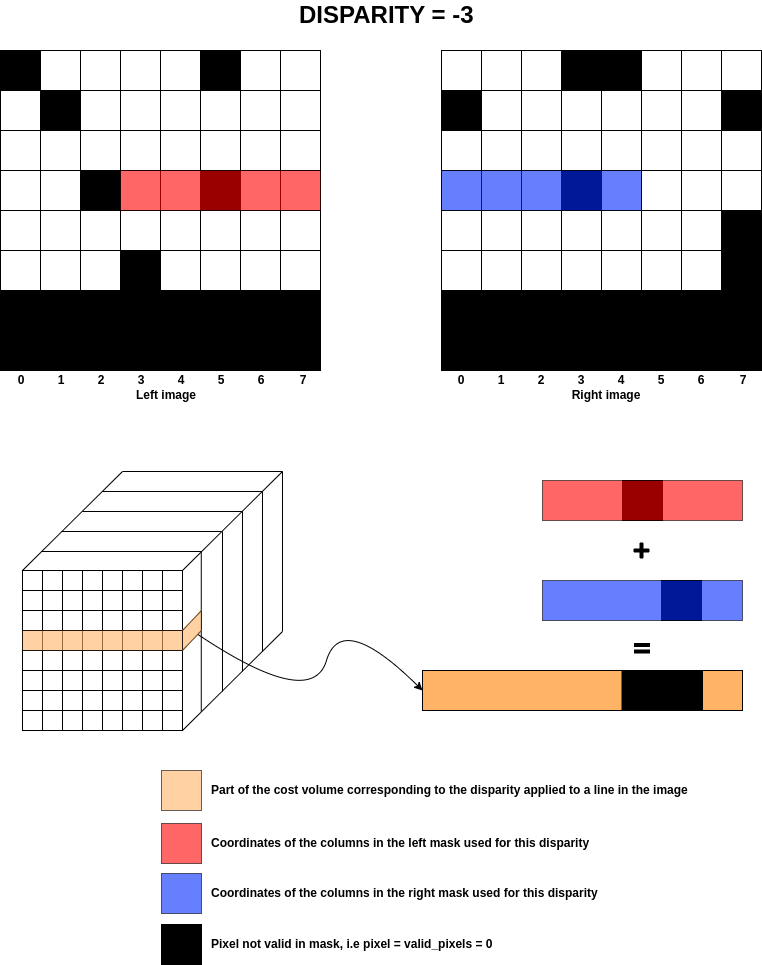
Warning
In the supixellic case, only one mask is calculated for .5 , .25 and .75 disparity.
To summarise the diagram, the implementation of the NaN assertions is as follows:
Equations
If
 invalid pixel in left mask for disparity d, then
invalid pixel in left mask for disparity d, then 
If
 invalid pixel in right mask for disparity d, then
invalid pixel in right mask for disparity d, then 